Imagine driving through a tunnel in an autonomous vehicle, unaware of a traffic jam caused by a crash ahead. Typically, you’d depend on the car in front to signal you to brake. But what if your vehicle could see beyond the car ahead and apply the brakes sooner?
MIT and Meta researchers have developed a computer vision technique that might make this possible in the future. Their method creates accurate 3D models of an entire scene, including areas hidden from view, using images from a single camera position. This technique leverages shadows to reveal what lies in obstructed parts of the scene.
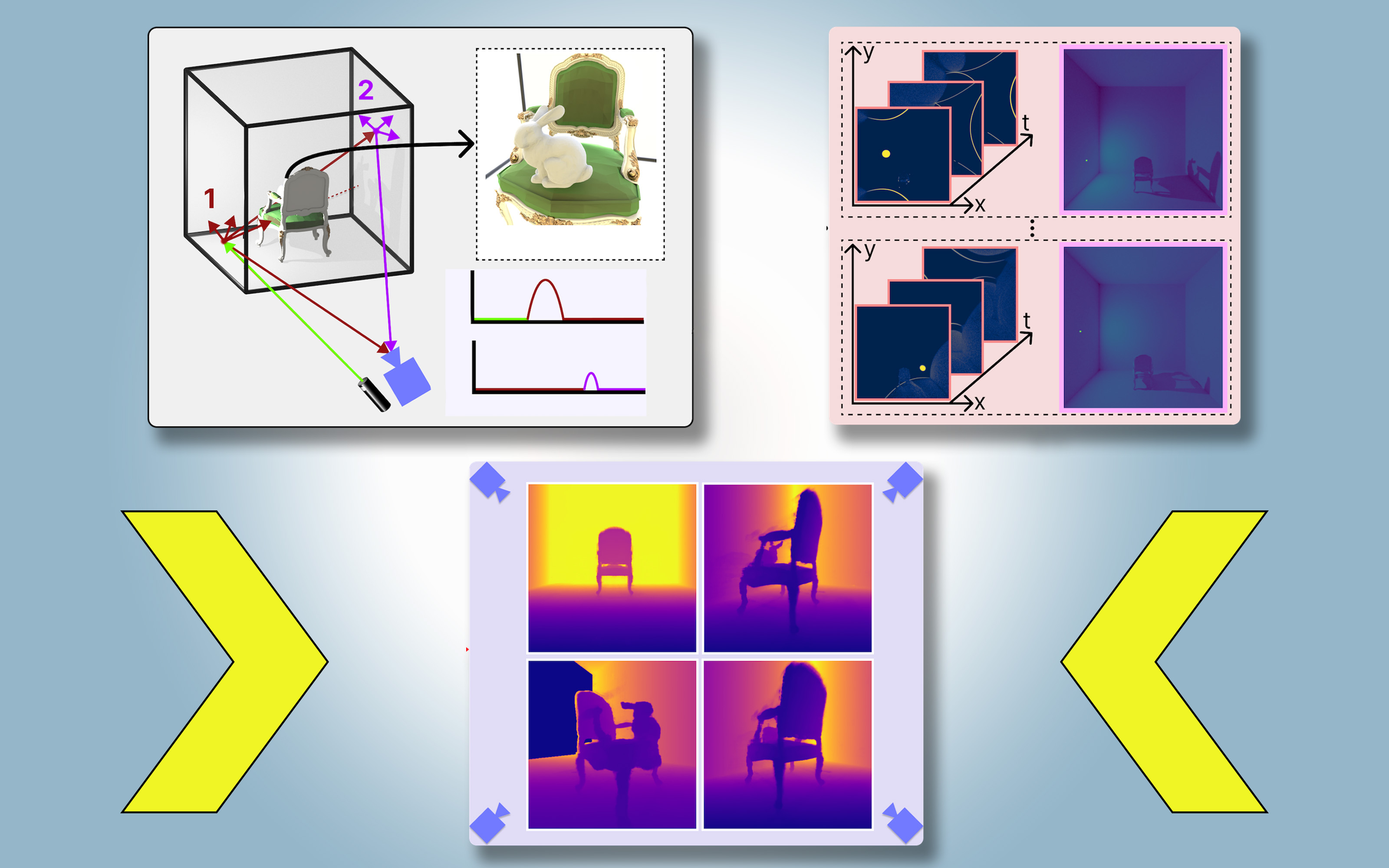
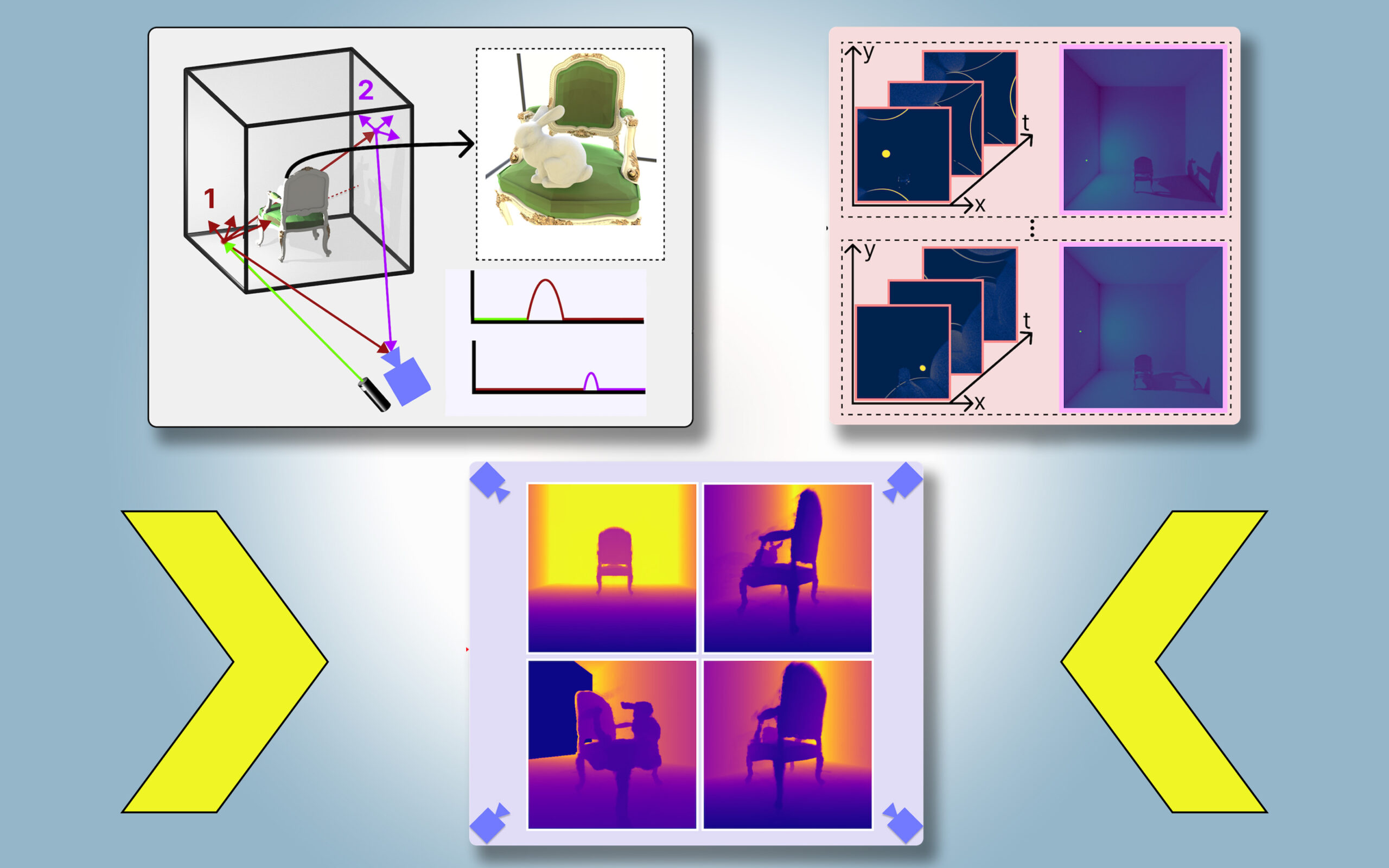
Named PlatoNeRF, inspired by Plato’s allegory of the cave, this approach combines lidar (light detection and ranging) technology with machine learning. It generates more accurate 3D reconstructions than some existing AI techniques and performs better in conditions where shadows are hard to see, such as high ambient light or dark backgrounds.
Beyond enhancing the safety of autonomous vehicles, PlatoNeRF could improve AR/VR headsets by allowing users to model a room’s geometry without needing to move around for measurements. It could also help warehouse robots locate items in cluttered environments more efficiently.
“Our key idea was to integrate two previously separate approaches — multibounce lidar and machine learning,” explains Tzofi Klinghoffer, an MIT graduate student and lead author of the paper on PlatoNeRF. “When you combine these, new opportunities emerge, providing the best of both worlds.”
Klinghoffer co-authored the paper with advisor Ramesh Raskar, an associate professor at MIT; senior author Rakesh Ranjan, a director at Meta Reality Labs; and other researchers from MIT and Meta. Their work will be presented at the Conference on Computer Vision and Pattern Recognition.
Reconstructing a full 3D scene from a single camera viewpoint is complex. Existing machine-learning approaches often guess what lies in occluded regions, sometimes hallucinating objects that aren’t there. Other methods infer hidden shapes using shadows in color images, but struggle when shadows are hard to detect.
For PlatoNeRF, the researchers used a new sensing modality called single-photon lidar, which provides high-resolution data by detecting individual photons. This lidar illuminates a target point in the scene, capturing light that bounces back directly and light that scatters before returning. PlatoNeRF uses this scattered light to gather additional depth information and shadow details, which it uses to infer the geometry of hidden objects.
By sequentially illuminating multiple points, PlatoNeRF reconstructs the entire 3D scene. “Each point we illuminate creates new shadows, helping us carve out the occluded regions,” Klinghoffer says.
Key to PlatoNeRF’s success is combining multibounce lidar with a neural radiance field (NeRF), a machine-learning model that encodes scene geometry into neural network weights. This combination leads to highly accurate scene reconstructions, especially when lidar resolution is lower, making it practical for real-world deployment.
“About 15 years ago, our group developed the first camera to see around corners using multiple bounces of light. This new work uses only two bounces, resulting in a high signal-to-noise ratio and impressive 3D reconstruction quality,” Raskar notes.
Future research will explore tracking more than two light bounces to improve reconstructions further and combining PlatoNeRF with color images for texture information. This approach, combining clever algorithms with ordinary sensors, could significantly enhance the accuracy of 3D reconstructions of hidden geometry.